□ 공부방법
ㅇ 교재 : 데이터분석 전문가 가이드(1차때 공부), 데이터분석 준전문가(데이터에듀)(2,3차때 공부)
ㅇ 공부기간 및 방법
- 1차(4주 공부) : 바로 붙어야 겠다는 강한 의지와 자신감을 갖고 시작했다. 시험범위에 하당하는 부분을 무작정 처음부터 끝까지 읽었다. 2~3번정도 읽고 제공되는 문제를 반복해서 풀었다. 여전히 방대한 양이어서 다 외우려고 하기보다는 흐름?을 익히는 정도로 외웠고, 도무지 머릿속에 들어오지 않는 부분들은 그냥 과감히 포기했다. 문제를 반복적으로 풀때는 쉬운 문제는 X쳐가면서 이후부턴 해당문제는 풀지않았기에 시간을 절약했다. 문제에서 반복적으로 나오는데 헷갈렸던 개념들 위주로 요약본을 만들었고 시험이 다가왔을때는 그것 위주로 봤다.
- 2차(2주 공부) : 1차응시 시험공부하는 동안 전체적으로 훑어봤기 때문에 시중에 떠도는 책 중 리뷰가 가장 많은것으로 구매해 공부했다. 이론 역시 2~3번정도 그냥 훑듯이 읽고 문제를 반복적으로 풀었다.
- 3차(1주 공부) : 2번의 결과가 참담해서 그냥 포기하고 잊고 지내다가, 아주 오랜 시간 뒤에 다시 생각이 나서 응시해놓고 거의 잊고있다가 마지막 딱 1주전에 데이터분석 준전문가 책(신규버젼)이 배달되어 그때부터 공부했다. 이론은 대충 1번 보고 바로 문제를 풀었다. 2회정도 푼것 같다. 문제를 풀면서 전혀 모르거나 기억 안나는 부분은 개념을 다시 찾아보고 그부분만 공부하는 방식으로 공부해 나가싿, 그리고 1차때 만들어 놨었던 요약본을 조금 더 추가(인터넷 카페를 통해 얻은 시험문제 정보들을 다 긁어모아 재정리) 해서 요약본을 시험 전날부터 봤다. 꼭 나올것만 같은 문제인데 공식을 못외운 경우가 있어서 시험응시장소에서 시험지 받기전까지 그부분만 공식을 머릿속으로 계속 읊었고 시험지를 받자마자 그 공식을 구석에 자그맣게 써놓고 문제를 풀었다. 다행히 그 공식을 이용해 푸는 문제가 나왔다.
□ 시험결과 및 변별력


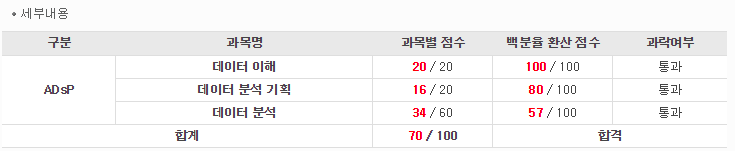
ㅇ 위에서부터 11회, 12회, 21회 adsp응시결과이다.
분명히 같은 범위이고 교재 내용은 변한게 없을터인데 점수의 변동폭이 너무 크다. 물론 내가 열심히 공부를 안한 요인이 클테지만 그것을 감안해도 변동폭이 큰부분은 변함없는 사실이다. 1과목과 2과목의 점수 변동성이 보이는가;;;;??
이렇게 난이도 조절이 잘 안되는것 같다. 그야말로 벼락치기를 해도 붙을만한 회차가 있고, 붙기 어려운 회차가 있을 수 있단 소리다.
시험을 연속적으로 본게 아니고 그 텀이 꽤나 길었기 때문에 기존의 공부내용은 머릿속에서 거의 잊혀져 있었다. 그런데 아이러니 하게도 시험공부량과 시험결과는 반비례 했다. 가장 열의도 없었도 공부기간도 짧게 했는데 합격했다.
어디까지나 내 기준이지만 점수만을 기준으로 본다면 회차별 난이도가 이렇게 들쑥날쑥한다는 것을 간접적으로 느낄 수 있을 것이다. 시험 응시할 때 참고하기 바란다.
□ 후기
ㅇ 명칭을 정의하는데 그 명칭 자체에 영어단어가 너무 많이 들어가 있다. 그냥 한글만 사용했을 뿐 그 뜻은 영어단어를 알아야 이해할 수 있는 것들이 너무나도 많다. 뭔가 이질감이 느껴진다. 이런 용어들이 굉장히 많이 나온다.
ㅇ 주관식에서는 재출제 되는 경우는 거의 없었다. (1~2문제 정도만이 과거 출제된 정도에서 나오는 듯)
ㅇ 실제 시험문제에서 그 개념과 범위가 공식교재 수준을 넘어서는 경우가 많이 나오는 것 같다. "한국데이터진흥원에서 규정한 문제출제범위가 맞는건가?", "한국데이터진흥원에서 명시한 교재를 토대로 나온 문제가 맞는건가?"라는 의심이 굉장히 많이 들었다. 시험을 보면 그 수준을 넘어서는 용어와 개념들이 어쩌다 한문제가 아니라 꽤나 많은 문제의 경우에서 말이다. 기호와 수식을 이용해서 표현하자면 대략 이런 느낌이다. ADsP를 수능과 비교하여 표현하겠다.
- (수능의 경우) 우리는 초/중/고 교육과정을 통해 A,B,C,D,E 개념을 배운 상태이다. 수능에서는 A,B,C,D,E 혹은 A+B, A+C+D+E, A*C*D 이런 느낌으로 기본개념 확인문제 부터 응용문제들이 출시된다 정도로 표현하겠다.
- (ADsP의 경우) 우리는 한국데이터진흥원이 명시한 공식교재인 "데이터분석 전문가 가이드"를 통해 A,B,C,D,E개념을 배운 상태이다. ADsP에서는 A,B,C,D,E 혹은 X, Y, Z, A+H+K, A*X*Z 이런느낌으로 (1)교재의 학습을 통해 풀수있는 문제와 (2)전혀 듣도보도 못한, 기본개념을 통해 응용도 할 수 없는 문제들이 나온다 정도로 표현하고 싶다.
즉 우리는 한국데이터진흥원이 명시한 공식교재인 "데이터분석 전문가 가이드"만을 씹어먹을 정도로 공부해도 ADsP에서 100점만점을 못받을 수 도 있단 소리다. 그만큼 난이도가 들쑥날숙한 것 같다. 바꿔말하면 공부량에 비례해서 당연히 합격을 보장하는 케이스도 있겠지만, 회차별 ADsP의 난이도 격차가 커서 열심히 공부한 사람이 합격을 못할수도, 대충 공부한 사람이 합격을 할수도 있을 것이란 소리다.(아래 표 참고)
| 경우1 | (1)에 해당하는 문제가 많이 나오고 (2)에 해당하는 문제가 적게나온 경우의 시험회차일 경우, 대충 공부했는데 합격할 수도 있다. |
| 경우2 | (1)에 해당하는 문제가 적게 나오고 (2)에 해당하는 문제가 많이 나오는 경우의 시험회차일 경우, 나름 열심히 공부했는데 합격하지 못할수도 있단 소리다. |
'통계 > 통계관련 자격증' 카테고리의 다른 글
| 사회조사분석사2급 공부과정 및 합격 후기 (0) | 2019.09.01 |
|---|




